Week 2 [Fri, Aug 13th] - Topics
Guidance for the item(s) below:
Given this is a first course in SE, tradition demands that we start by defining the subject. However, we are not going to spend a lot of time going through definitions of SE. Instead, let's look at an extract from the very first chapter of a very famous SE book, with the aim of providing some inspiration but also an appreciation of the challenges ahead.
Guidance for the item(s) below:
Broadly speaking, there are two approaches to doing a software project. Those two approaches are also highly relevant to the way this module is run, and how it is different from most SE modules elsewhere.
Let's learn about those two approaches early so that we can better understand how this module works.
Can explain sequential process models
The sequential model, also called the waterfall model, models software development as a linear process, in which the project is seen as progressing steadily in one direction through the development stages. The name waterfall stems from how the model is drawn to look like a waterfall (see below).
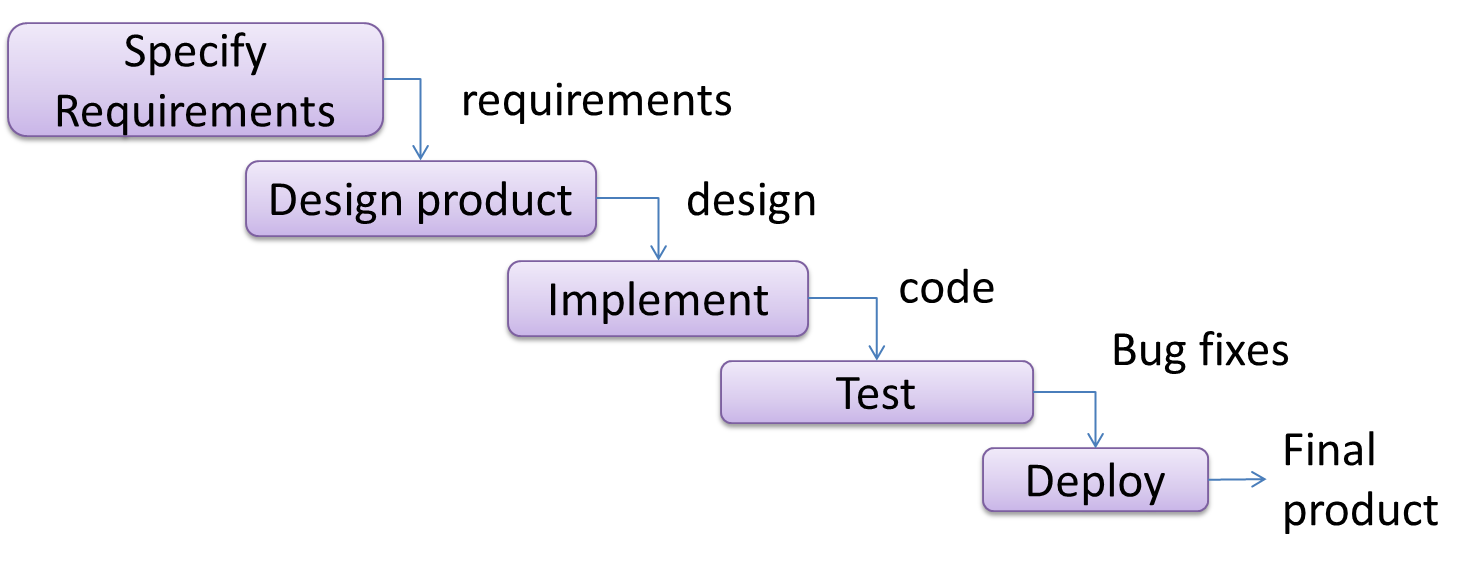
When one stage of the process is completed, it should produce some artifacts to be used in the next stage. For example, upon completion of the requirements stage, a comprehensive list of requirements is produced that will see no further modifications. A strict application of the sequential model would require each stage to be completed before starting the next.
This could be a useful model when the problem statement is well-understood and stable. In such cases, using the sequential model should result in a timely and systematic development effort, provided that all goes well. As each stage has a well-defined outcome, the progress of the project can be tracked with relative ease.
The major problem with this model is that the requirements of a real-world project are rarely well-understood at the beginning and keep changing over time. One reason for this is that users are generally not aware of how a software application can be used without prior experience in using a similar application.
Can explain iterative process models
The iterative model (sometimes called iterative and incremental) advocates having several iterations of SDLC. Each of the iterations could potentially go through all the development stages, from requirements gathering to testing & deployment. Roughly, it appears to be similar to several cycles of the sequential model.
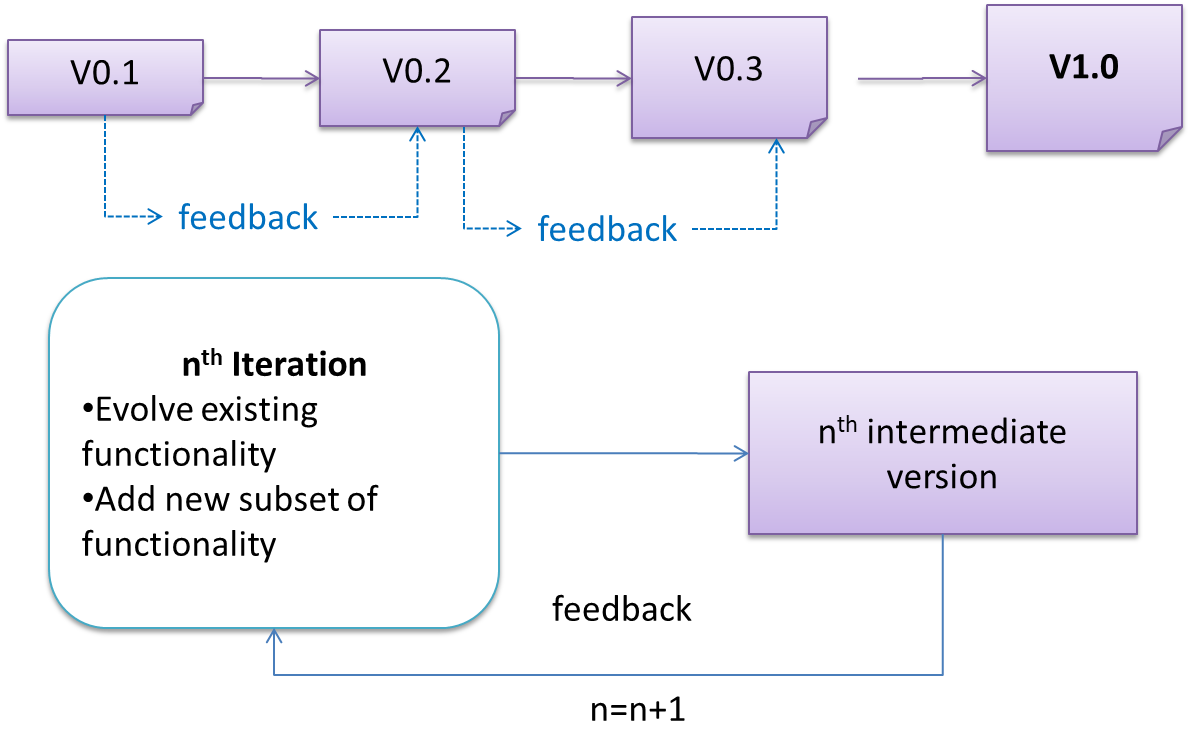
In this model, each of the iterations produces a new version of the product. Feedback on the new version can then be fed to the next iteration. Taking the Minesweeper game as an example, the iterative model will deliver a fully playable version from the early iterations. However, the first iteration will have primitive functionality, for example, a clumsy text based UI, fixed board size, limited randomization, etc. These functionalities will then be improved in later releases.
The iterative model can take a breadth-first or a depth-first approach to iteration planning.
- breadth-first: an iteration evolves all major components in parallel e.g., add a new feature fully, or enhance an existing feature.
- depth-first: an iteration focuses on fleshing out only some components e.g., update the backend to support a new feature that will be added in a future iteration.
Most projects use a mixture of breadth-first and depth-first iterations i.e., an iteration can contain some breadth-first work as well as some depth-first work.
Guidance for the item(s) below:
Next, let's get started learning Java. First, a bit about the language itself.
Guidance for the item(s) below:
As with any language, the first step is to install the language in your computer. After that, you write a simple HelloWorld program, and get it running.
Java 11 can be downloaded from here.
Guidance for the item(s) below:
Now that you know how to write the simplest of Java programs, you can move onto learning about basic language concepts, starting with data types.
Guidance for the item(s) below:
Next up is learning how to control the flow of a Java program.
Guidance for the item(s) below:
🤔 In case you are puzzled by the sudden change of topic, it's because we take an iterative approach to covering topics, as explained in the panel below:
Guidance for the item(s) below:
Guidance for the item(s) below:
Now that we know what RCS is in general, we can try to practice it ourselves using a specific tool i.e., Git.
The following section gives a specific scenario that includes the steps of initializing a Git repository.
If you are new to Git, you are highly recommended to follow those steps in your own computer to get some hands-on practice as you learn Git usage.
Can create a local Git repo
Let's take your first few steps in your Git (with GitHub) journey.
0. Take a peek at the full picture(?). Optionally, if you are the sort who prefers to have some sense of the full picture before you get into the nitty-gritty details, watch the video in the panel below:
1. The first step is to install SourceTree, which is Git + a GUI for Git. If you prefer to use Git via the command line (i.e., without a GUI), you can install Git instead.
2. Next, initialize a repository. Let us assume you want to version control content in a specific directory. In that case, you need to initialize a Git repository in that directory. Here are the steps:
Create a directory for the repo (e.g., a directory named things).
Windows: Click File → Clone/New…. Click on Create button.
Mac: New... → Create New Repository.
Enter the location of the directory (Windows version shown below) and click Create.
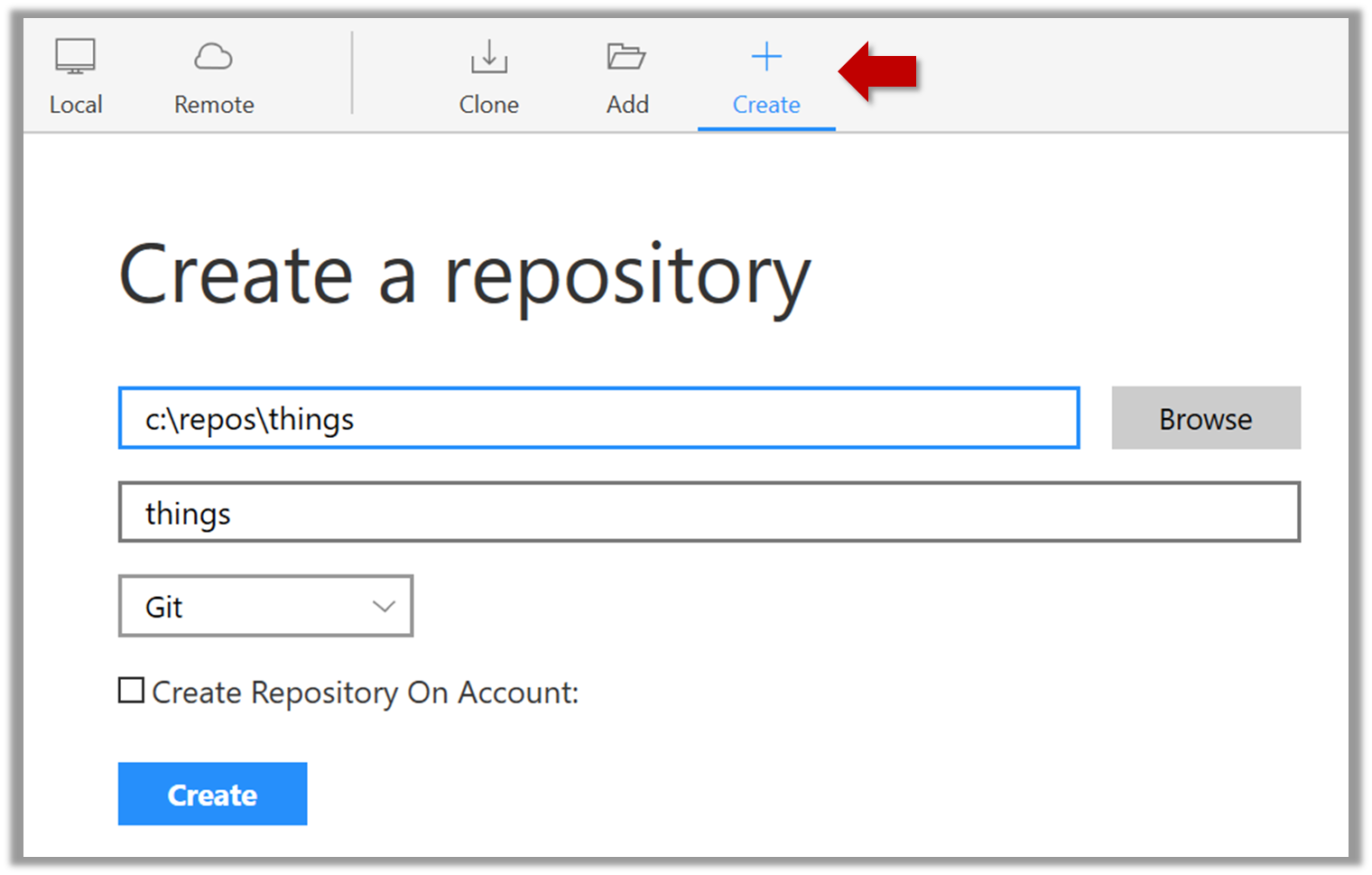
Go to the things folder and observe how a hidden folder .git has been created.
Windows: you might have to configure Windows Explorer to show hidden files.
Open a Git Bash Terminal.
If you installed SourceTree, you can click the Terminal button to open a GitBash terminal.
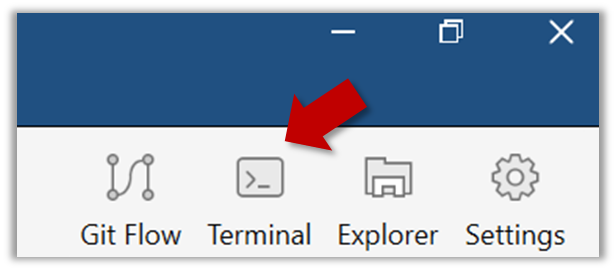
Navigate to the things directory.
Use the command git init which should initialize the repo.
$ git init
Initialized empty Git repository in c:/repos/things/.git/
You can use the command ls -a to view all files, which should show the .git directory that was created by the previous command.
$ ls -a
. .. .git
You can also use the git status command to check the status of the newly-created repo. It should respond with something like the following:
git status
# On branch master
#
# Initial commit
#
nothing to commit (create/copy files and use "git add" to track)
Guidance for the item(s) below:
For the next few sections, the drill is the same: first learn the high-level explanation of a revision control concept, and then follow the given scenarios yourself to learn how to apply that concept using Git.
Can commit using Git
After initializing a repository, Git can help you with revision controlling files inside the working directory. However, it is not automatic. It is up to you to tell Git which of your changes (aka revisions) should be committed to its memory for later use. Saving changes into Git's memory in that way is often called committing and a change saved to the revision history is called a commit.
Working directory: the root directory revision-controlled by Git (e.g., the directory in which the repo was initialized).
Commit (noun): a change (aka a revision) saved in the Git revision history.
(verb): the act of creating a commit i.e., saving a change in the working directory into the Git revision history.
Here are the steps you can follow to learn how to work with Git commits:
1. Do some changes to the content inside the working directory e.g., create a file named fruits.txt in the things directory and add some dummy text to it.
2. Observe how the file is detected by Git.
The file is shown as ‘unstaged’.
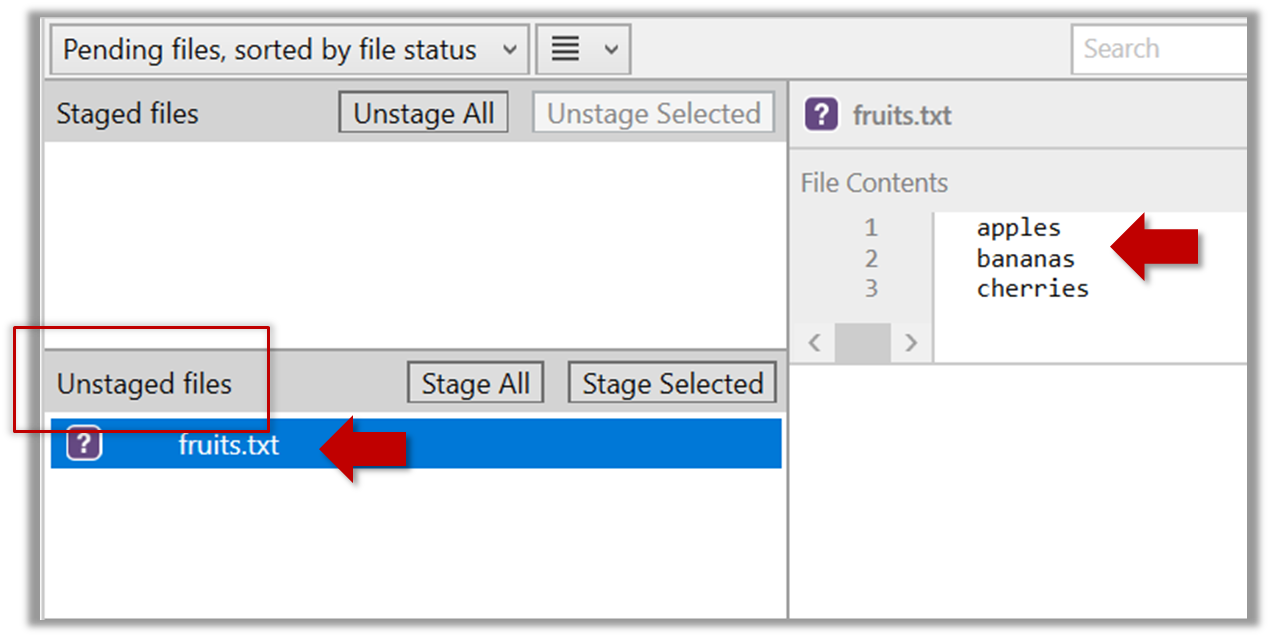
You can use the git status command to check the status of the working directory.
git status
# On branch master
#
# Initial commit
#
# Untracked files:
# (use "git add <file>..." to include in what will be committed)
#
# a.txt
nothing added to commit but untracked files present (use "git add" to track)
3. Stage the changes to commit: Although Git has detected the file in the working directory, it will not do anything with the file unless you tell it to. Suppose you want to commit the current changes to the file. First, you should stage the file.
Stage (verb): Instructing Git to prepare a file for committing.
Select the fruits.txt and click on the Stage Selected button.
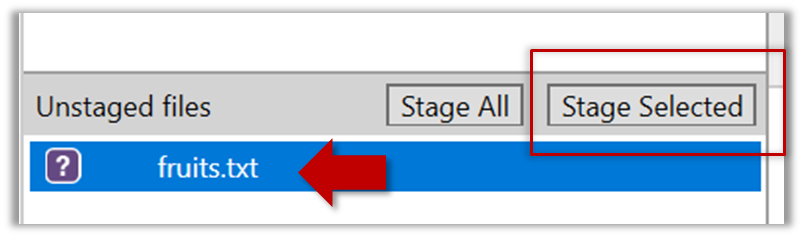
fruits.txt should appear in the Staged files panel now.
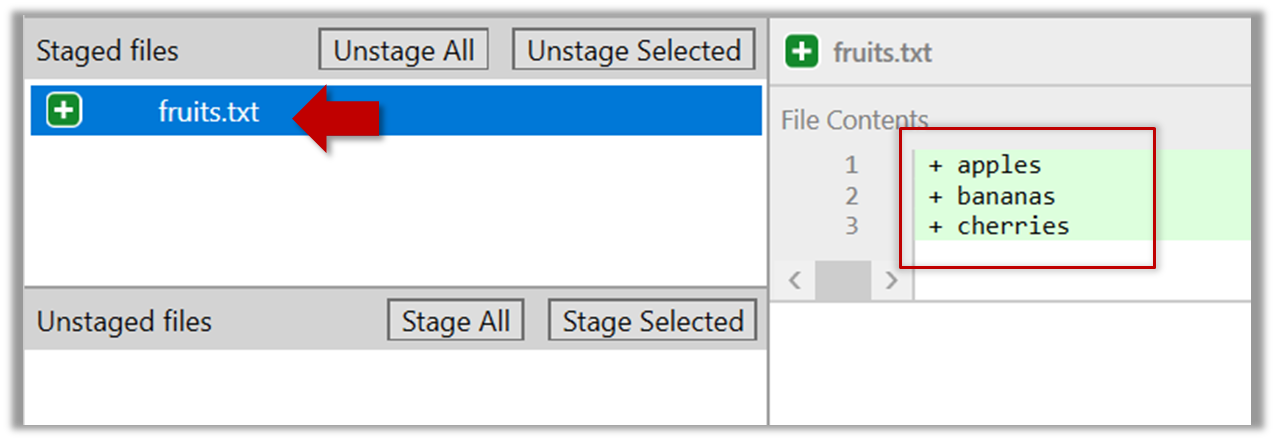
You can use the stage or the add command (they are synonyms, add is the more popular choice) to stage files.
git add fruits.txt
git status
# On branch master
#
# Initial commit
#
# Changes to be committed:
# (use "git rm --cached <file>..." to unstage)
#
# new file: fruits.txt
#
4. Commit the staged version of fruits.txt.
Click the Commit button, enter a commit message e.g. add fruits.txt into the text box, and click Commit.
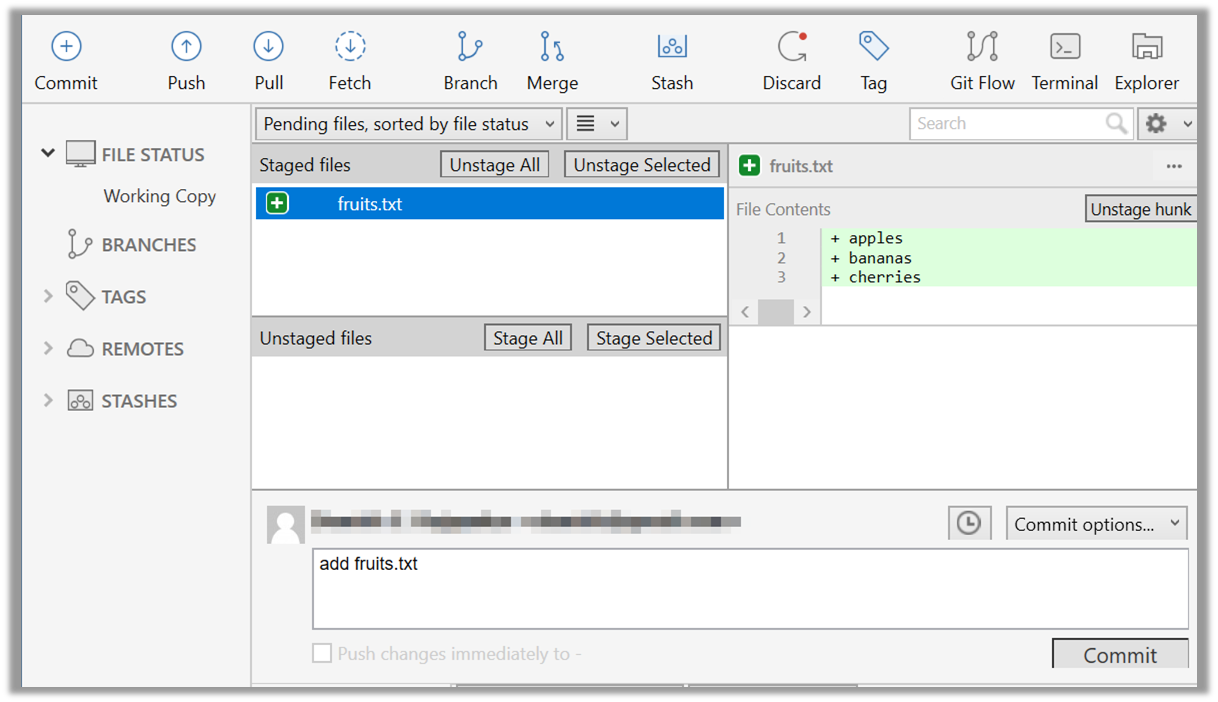
Use the commit command to commit. The -m switch is used to specify the commit message.
git commit -m "Add fruits.txt"
You can use the log command to see the commit history.
git log
commit 8fd30a6910efb28bb258cd01be93e481caeab846
Author: … < … @... >
Date: Wed Jul 5 16:06:28 2017 +0800
Add fruits.txt
Note the existence of something called the master branch. Git allows you to have multiple branches (i.e. it is a way to evolve the content in parallel) and Git auto-creates a branch named master on which the commits go on by default.
5. Do a few more commits.
Make some changes to
fruits.txt(e.g. add some text and delete some text). Stage the changes, and commit the changes using the same steps you followed before. You should end up with something like this.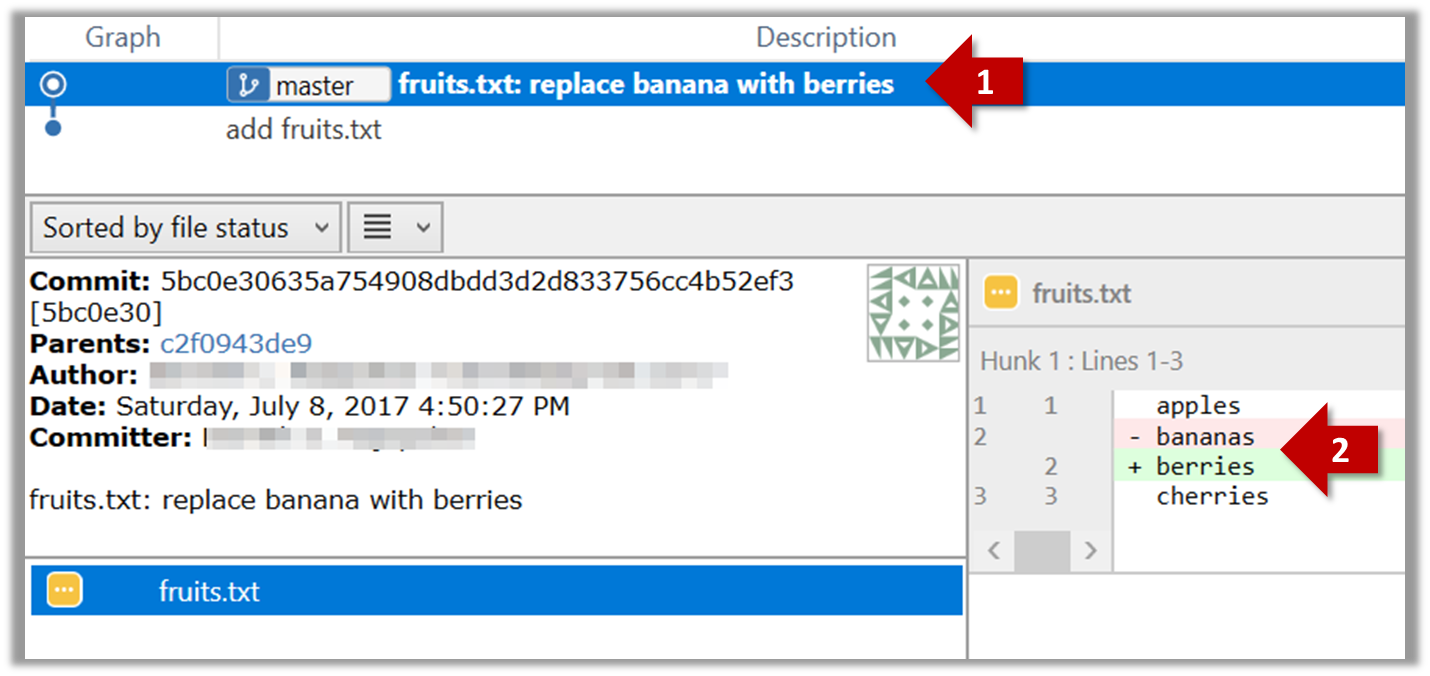
Next, add two more files
colors.txtandshapes.txtto the same working directory. Add a third commit to record the current state of the working directory.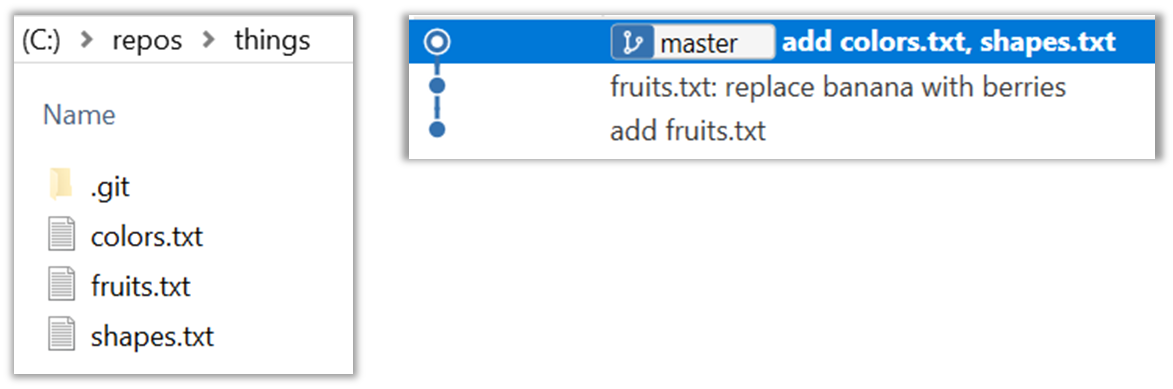
6. See the revision graph: Note how commits form a path-like structure aka the revision tree/graph. In the revision graph, each commit is shown as linked to its 'parent' commit (i.e., the commit before it).
To see the revision graph, click on the History item on the menu on the right edge of SourceTree.
The gitk command opens a rudimentary graphical view of the revision graph.
Guidance for the item(s) below:
Having learned how to use Git in your own computer, let's also learn a bit about working with remote code repositories too. Yes it's a bit too much to take in one week but we want you to start using Git in your iP from the very beginning.
Guidance for the item(s) below:
As you are likely to be using an IDE for the iP, let's learn at least enough about IDEs to get you started using one.
Guidance for the item(s) below:
As you know, one of the objectives of the iP is to raise the quality of your code. We'll be learning about various ways to improve the code quality in the next few weeks, starting with coding standards.